Understanding the working of computers and how programs are run is important to understand computer architecture.
In this post, we won’t go into the micro-level implementation details of modern architecture but will cover the overall design.
In computer science, computer architecture is a set of rules and methods that describe the functionality, organization, and implementation of computer systems. The architecture of a system refers to its structure in terms of separately specified components of that system and their interrelationships.
Architecture Types
There are two main types of computer architectures in system design:
- Von Neumann architecture
- Harvard Architecture
Von Neumann Architecture
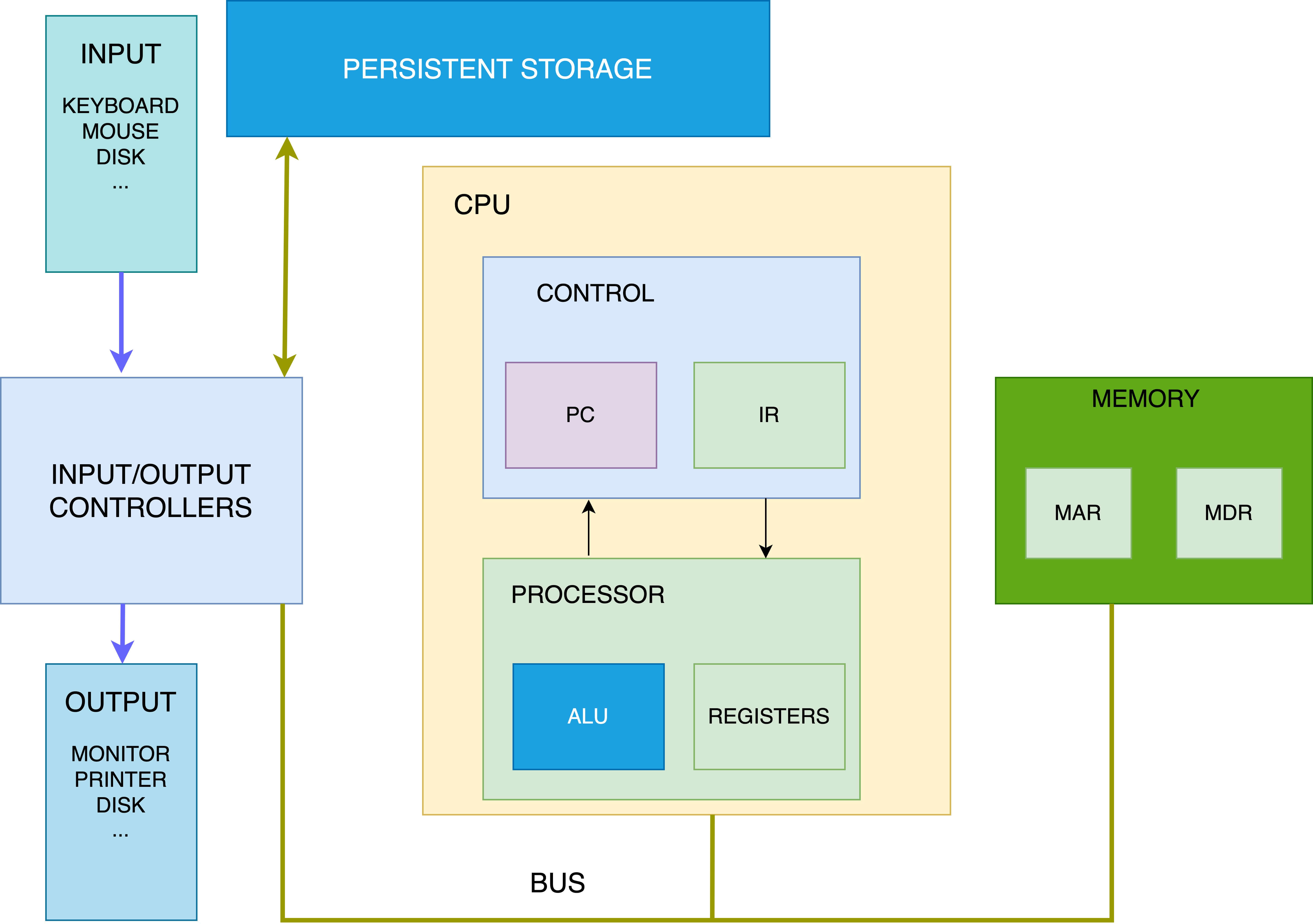
Von Neumann architecture is the design upon which modern general-purpose computers are based.
Von Neumann computer systems contain three main building blocks:
- the central processing unit (CPU)
- Memory
- input/output devices (I/O)
These three components are interconnected using the system bus(es).
The key concepts of Von Neumann architecture are as follows:
- Programs (instructions) and data are both located in the same memory. This is also the reason behind the Von Neumann bottleneck.
- It follows the fetch and execute cycle. Instructions are fetched from memory one at a time and in order (serially) and the processor decodes and executes an instruction, before cycling around to fetch the next instruction. The cycle continues until no more instructions are available. To execute one instructions it needs at-least 2 cycles.
Harvard Architecture
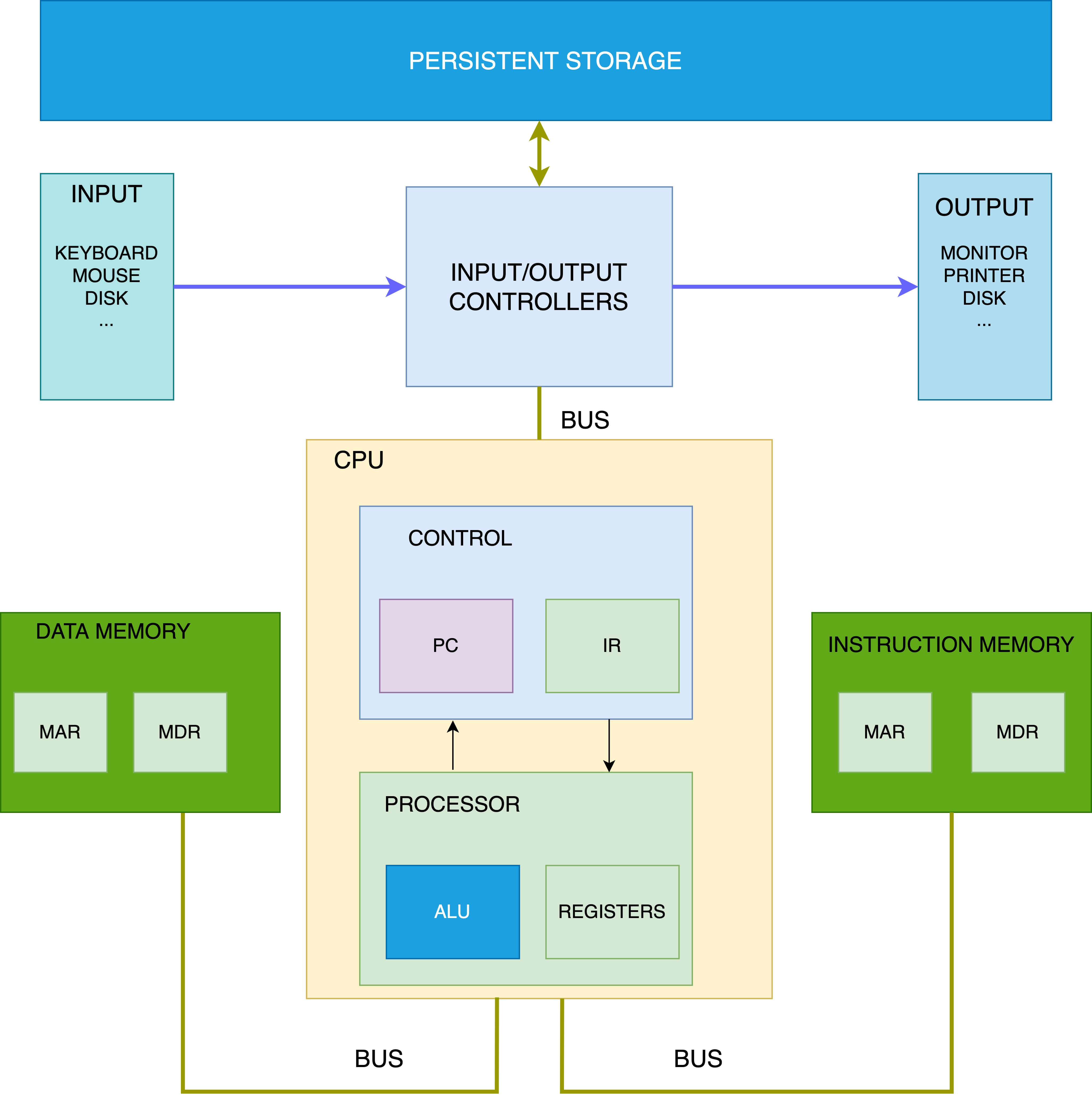
Harvard Architecture is the design upon which modern microcontrollers and computer chips are designed.
Harvard architecture processors or microcontroller systems contain the followings building blocks:
- The central processing unit (CPU)
- Data Memory
- Instruction Memory
- Input/Output (I/O) Devices
The key concepts of Harvard architecture
- Programs (Instructions) and data are kept in separate memories.
- Processor access these memories using separate data and address buses.
- It also follows the fetch and execute cycle. To execute one instruction it needs 1 cycle.
Basic of architectural blocks
Memory Unit
CPU interfaces with the memory unit for accessing instructions and data. The memory can be RAM (Random Access Memory) or ROM (Read Only Memory).
RAM (random access memory), meaning that the CPU can access any value at any time.
ROM (read-only memory), memory used only for reading and write not allowed.
Memory operations
There are two key operations performed on memory
- Fetch (address). Returns value stored at that address without altering
- Store (address, value), writes the value at that given address
Communication between memory and the processor unit consists of two registers:
- The memory address register (MAR) holds the address of the current instruction that is to be fetched from memory or the address in memory to which data is to be transferred
- The memory data register (MDR) holds the contents found at the address held in the MAR, or data that is to be transferred to primary storage
Processor Unit
The processor unit consists of two parts. The first is the arithmetic/logic unit (ALU), which performs mathematical operations, such as addition, subtraction, and logical or, to name a few. Modern ALUs typically perform a large set of arithmetic operations. The second part of the processing unit is a set of registers. A register is a small, fast unit of storage used to hold program data and the instructions that are being executed by the ALU. Crucially, there is no distinction between instructions and data in the von Neumann architecture. Instructions are data. Each register is therefore capable of holding one data word.
The arithmetic logic unit ALU is hardware that implements Arithmetic and Logical Operations
- ALU capable of performing ADD, SUBTRACT, AND, OR, and NOT operations. Modern ALU can perform many more operations.
- The accumulator (ACC) is a special-purpose register and is used by the ALU to hold the data being processed and the results of calculations
Control Unit
The control unit drives the execution of program instructions by loading them from memory and feeding instruction operands and operations through the processor. It also includes some storage to keep track of the execution state and to determine its next action to take: the program counter (PC) keeps the memory address of the next instruction to execute, and the instruction register (IR) stores the instruction, loaded from memory, that is currently being executed.
- Manages the processor unit
- Control units have the program counter (PC) register that holds the memory address of the next instruction to be fetched from primary storage
- The current instruction register (IR) holds the instruction that is currently being decoded and executed
Input/Output (I/O) Units
The input and output units enable the system to send/receive data to/from different connected devices. The I/O controllers provide mechanisms for loading a program’s instructions and data into memory, storing its data outside of memory to persistent storage, and displaying its results to users.
The Input unit consists of the set of devices that enable a user to send custom inputs to programs. The most common forms of input devices today are the keyboard and mouse. Cameras and microphones are other examples.
The Output unit consists of the set of devices that relay results of computation from the computer back to the user through output devices or storing it in the persistent storage. For example, the monitor is a common output device. Other output devices include speakers, headphones, etc.
Some modern devices, such as the touchscreen, act as both input and output, enabling users to both input and receive data from a single unified device.
Bus
In computer architecture, a bus is a communication system that transfers data between components inside a computer, or between computers.
The types of buses are Data, Control and Address buses.
Data Bus
This bus is referred to as a bi-directional bus, which means “bits” can be carried in both ways. This bus is used to transfer data and instructions between the processor, memory unit, and the input/output.
Address bus
Transfer the memory address specifying where the relevant data needs to be sent or retrieved from.
Control bus
This is also a bi-directional bus used to transfer control/commands/status data from the CPU in order to control and coordinate all the activities within the computer.
Persistent Storage
Solid-state, hard drives, flash drives devices are considered persistent storage that acts as both input and output devices. These storage devices act as input devices when they store program executable files that the operating system loads into computer memory to run, and they act as output devices when they store files to which program results are written.
Applications
Harvard architecture is commonly used in embedded systems, i.e. computer systems that are designed purposefully to perform a specific set of operations and are often used in situations where the speed of operation is very important. For example, microcontrollers used in the washing machine, microwave cooking device, etc mostly use Harvard Architecture. The instruction memory can be implemented as a read-only memory (ROM), which protects the programs from accidental or deliberate changes by hacking. Whereas, Von Neumann’s architecture allows for the instructions and data to be saved in the same memory, which can be exploited by hackers who could disguise instructions (malware) as data that the processor may execute unknowingly when attempting to read the data.
Nonetheless, Von Neumann’s architecture enables more flexible use of the main memory, which allows the processor to run a variety of programs that are not known in advance. It is more useful for general-purpose computing systems that are expected to accommodate the varying needs of the end-users, for example, run numerous applications and switch between different tasks.
Most advanced processors implement Harvard Architecture at a very low level by using separate cache for data and instructions, such as L1 data and L1 instruction cache as used in Intel, AMD or arm processors. Beyond L1 cache rest of the system follows Von Neumann architecture.

In the above diagram L1 I cache means L1 Instruction cache, where instructions are stored.
In the above diagram L1 D cache means L1 Data cache, where data are stored.
Execution of instructions is faster in Harvard Architecture because fetching data and instruction are separate, in general, take fewer cycles.
The distinctions between modern processors are difficult to categorize concerning such pure theoretical models. These days, the line between von Neumann and Harvard is getting blurred.
Architecturally, i.e., concerning what software sees, modern processors use the serial von Neumann model. However, most high-performance processors use out-of-order execution which allows operations to be executed in a non-serial manner but their effects are committed in program order.